从 iPhone 诞生至今,智能手机风靡全球已将近 20 年,智能手机操作系统 iOS 和 Android 也成为当仁不让的顶流般的存在,而作为其背后的灵魂,移动应用也随着技术的发展已经越来越丰富。如果从技术层面来讲,移动 App 也从最开始单一的原生开发(Native App)模式,演变出了混合开发(Hybird App)、网页应用开发(Web App),为什么会有这种发展的变化呢?
因为原有的 Native App 有一个明显的痛点,就是相同的功能需要在不同的平台上都实现一遍,所以就有了一个很迫切的需求,能否只需要写一次代码,就可以在各个端都运行?
移动跨平台的逻辑
跨平台开发从本质上讲是为了增加业务代码的复用率,减少因为要适配多个平台带来的工作量,从而降低开发成本。在提高业务专注度的同时,能够为用户提供一致的用户体验,实现“多快好省”的效果。
跨平台是跨哪些平台?怎么样的跨平台逻辑?从当前的实际情况来看,移动端跨平台需求主要集中在以下 3 点:
- 桌面端跨移动端:桌面向移动端过渡的早期,希望 PC Web 与移动 Web 复用同一套代码。
- Native 跨 Web:一套功能差不多的 Web 页能够在端外访问,需要跨 Native App 与 Web。
- 跨系统双端:出于开发效率等原因,希望 Android、iOS 双端复用一套业务代码,这也是目前主要的需求点。
而放眼未来,我们预见可能还会有这些跨平台需求:
- 跨小程序/轻应用:即用即走的轻量级应用,如各平台的小程序、 Android 快应用、iOS App Clips。
- 跨 IoT 设备:各种有显示屏的设备都会成为新的入口,如车载设备、智能电视等。
移动跨平台方案的发展
不仅是移动应用的开发模式在持续的演变,跨平台开发方案也紧紧的跟随着开发模式的变化持续的演进,按照技术的发展,跨平台方案可以分为三个时代。
1、Web 容器时代
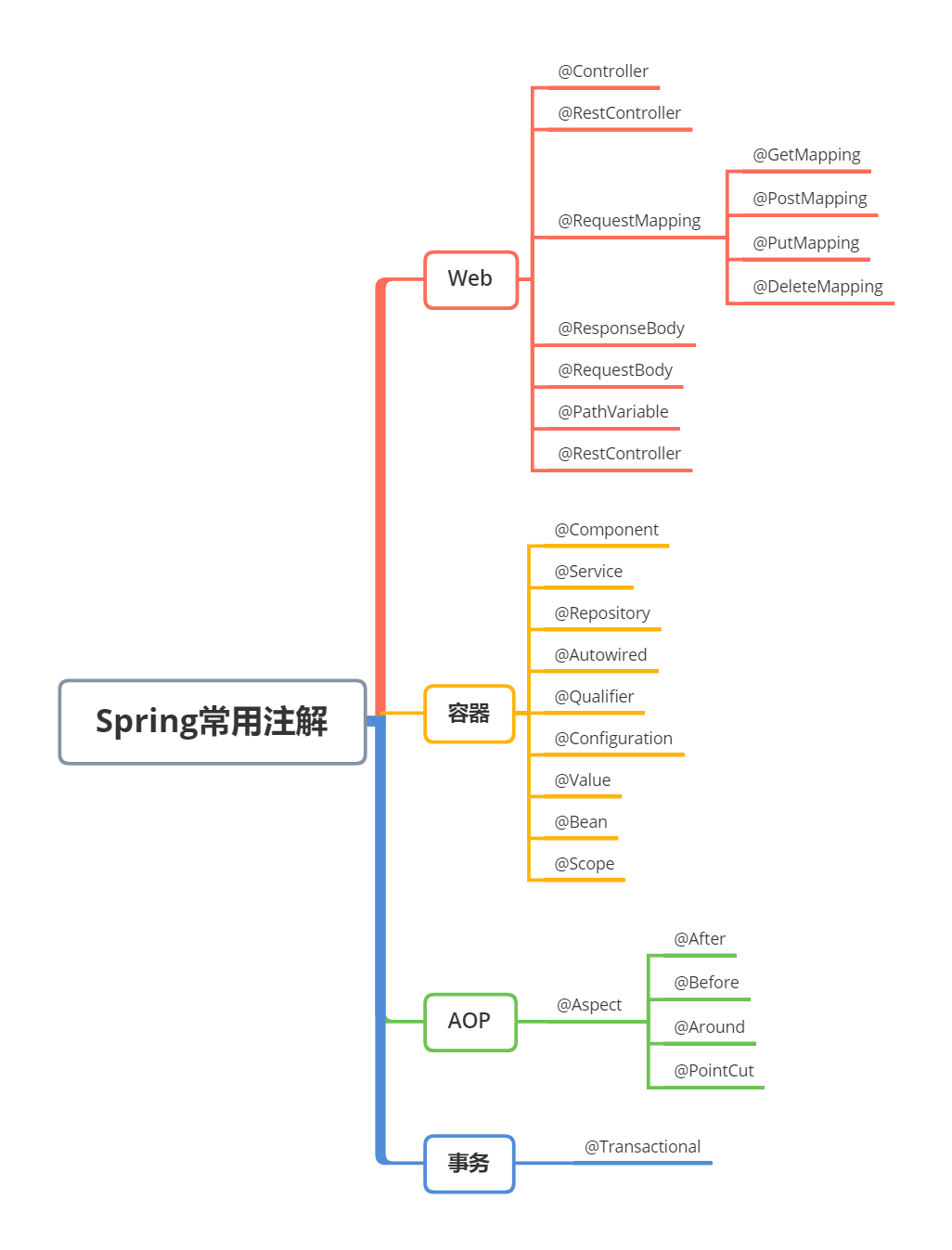
基于 Web 相关技术通过浏览器组件来实现界面及功能,典型的框架包括 Cordova、Ionic 和微信小程序。Web 时代的方案,主要采用的是原生应用内嵌浏览器控件 WebView 的方式进行 HTML5 页面渲染,并定义 HTML5 与原生代码交互协议,将部分原生系统能力暴露给 HTML5,从而扩展 HTML5 的边界。这类交互协议,就是我们通常说的 JS Bridge。
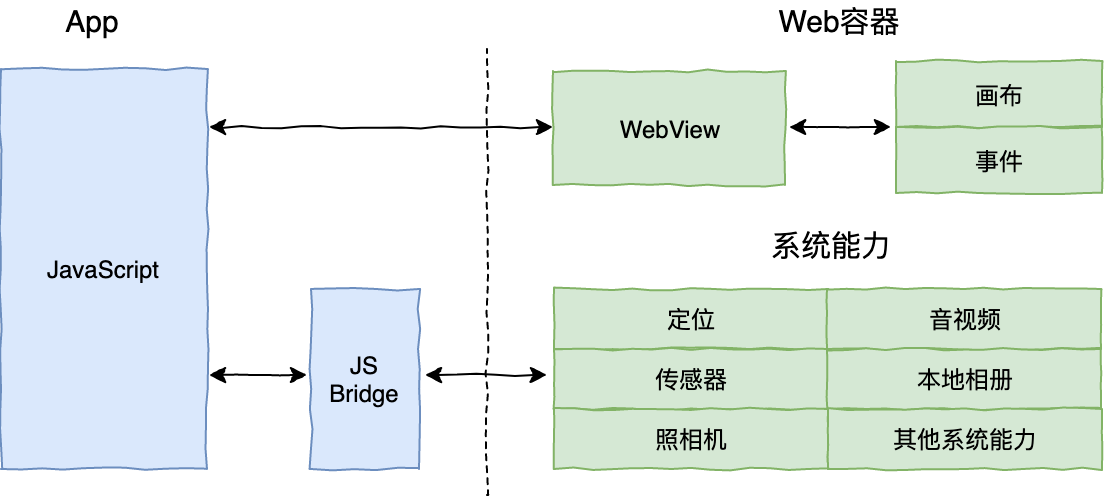
2、泛 Web 容器时代
采用类 Web 标准进行开发,但在运行时把绘制和渲染交由原生系统接管的技术,代表框架有 React Native、Weex 和快应用等。过渡到泛 Web 容器时代,优化了 Web 容器时代的加载、解析和渲染这三大过程,把影响它们独立运行的 Web 标准进行了裁剪,以相对简单的方式支持了构建移动端页面必要的 Web 标准(如 Flexbox 等),也保证了便捷的前端开发体验;同时,这个时代的解决方案基本上完全放弃了浏览器控件渲染,而是采用原生自带的 UI 组件实现代替了核心的渲染引擎,仅保持必要的基本控件渲染能力,从而使得渲染过程更加简化,也保证了良好的渲染性能。
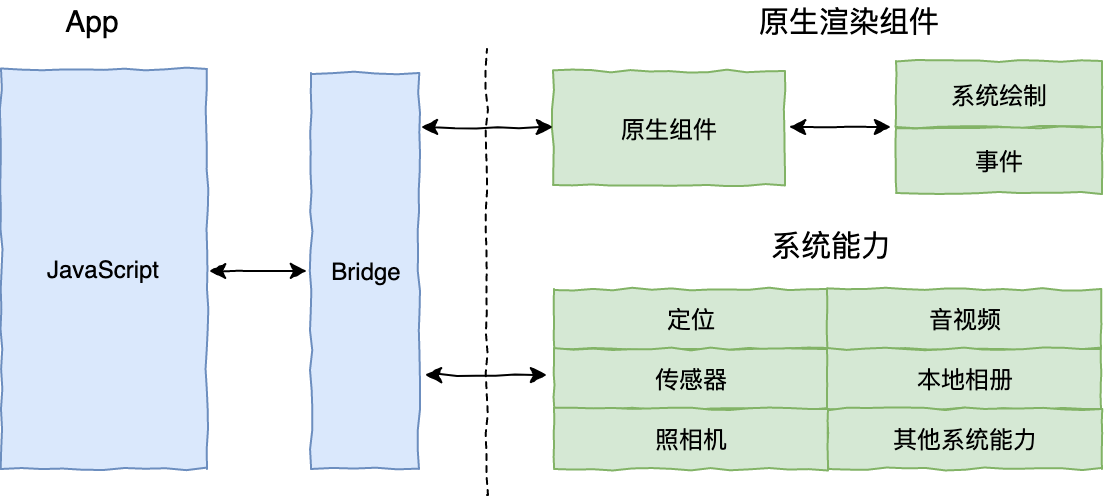
3、自绘引擎时代
自带渲染引擎,客户端仅提供一块画布即可获得从业务逻辑到功能呈现的多端高度一致的渲染体验。Flutter,是为数不多的代表。Flutter 开辟了一种全新的思路,即从头到尾重写一套跨平台的 UI 框架,包括渲染逻辑,甚至是开发语言。
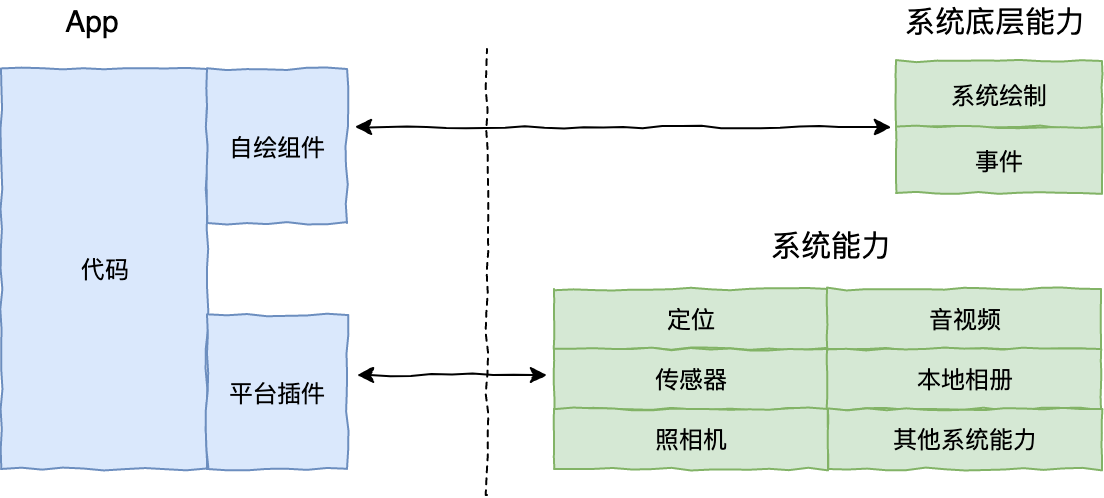
移动跨平台技术方案的对比
对比现有的跨平台技术和解决方案也可以分为三类,分别是 Web 跨端、容器跨端、小程序跨端。
1、Web 跨端
Web 跨端比较好理解,因为 Web 与生俱来就有跨端的能力,因为只要有浏览器或 WebView,现在绝大多数端上(甚至包括封闭的小程序生态)都支持 Webview,所以只要开发网页然后投放到多个端即可轻松跨平台,例如 Web App、PWA(Progressive Web Apps)、Hybrid App、PHA(Progress Hybrid App)。
优点:
- 没有额外的学习成本,一套基础技术吃天下
- 不依赖特殊的配套设施,从开发、调试到运维等所有工程化环节都是通用的
- 背靠 npm 庞大的生态,百万模块,应有尽有
缺点:
- 经常会遇到白屏、卡顿等情况,用户的体验不佳
- 无法调用系统的权限,例如多媒体、蓝牙、相机等
- 性能不好,对内存的消耗大
2、容器跨端
另一种统一多端的思路是将 Native 定制成标准容器,让同一份代码跑在一个个标准容器中。比较典型的代表是 React Native 、Flutter、Weex,这类方案通过尽可能的取长补短,综合了 Web 生态和 Native 组件,让 JS 执行代码后用 Native 的组件进行渲染,以解决抛弃 Web 历史包袱的问题。
具体来讲 React Native 可以跨 Android、iOS、Web、Windows 四端,Flutter 可以跨 Android、iOS、Web、Linux 四端,Weex 可以跨 Android、iOS、Web 三端。
优点:
- Flutter 快速的开发,富有表现力的精美 UI 和类似本机的性能
- React Native 专注于用户界面,使应用程序开发人员能够构建高度可靠的界面
- Weex 页面就像开发普通网页一样;在渲染 Weex 页面时和渲染原生页面一样
缺点:
- React Native 没有提供的需要自定义的应用,仍然需要使用原生开发
- Flutter 构建的应用程序文件很大,没有广泛的资源基础,这意味着可能找不到开发所需的第三方库和包
- Weex 由于起步比较晚,社区活跃度不如 RN,资料和开源项目也相对较少
3、小程序跨端
小程序跨端也比较好理解,就是让同样代码的小程序能够运行在多个 App 中,例如开发完一个小程序除了让其运行在微信之外,还能运行在支付宝、百度等超级 App,甚至是自己的 App 中。
如果说小程序仍然是依靠 Web 技术运行的,那为什么还要单独去使用小程序呢?就像前面所说到的一样,Web 始终没法调用例如相机、蓝牙等这样的权限,并且用户使用体验会收到一定的影响。而小程序则不同,小程序具有强大的 Web 渲染引擎、提供丰富组件、支持本地缓存、避免 DOM 泄露等,并且其初衷是开放,例如微信、支付宝这样的超级 App 也都相继开放了小程序上架能力,小程序逐渐成为跨 App 的正规方式。
后期也甚至出现了例如 FinClip 这样的小程序容器,可以让个人或企业自己的 App 具备小程序的运行能力,让其他 App 能够具有超级 App 一致的小程序跨端能力。
优势:
- 具备类似 Native App 的体验度,使用较为流畅丝滑
- 可以获取用户的相册、多媒体、蓝牙等基础权限
- 可以通过便捷化的上下架方式完成相关页面和业务的热更新
缺点:
- 大平台的框架标准不统一,会稍微有影响,但都大同小异,W3C 也在做小程序的标准化工作
- 部分的插件会用到原生相关的技术