idea循环依赖aAnnotation processing is not supported for module cycles.
错误现象 Error:java: Annotation processing is not supported for module cycles. Please ensure that all modules from cycle [book-rpc,book-api] are excluded from annotation processing
Understanding the ‘enable.auto.commit’ Kafka Consumer property
Kafka Consumers read messages from a Kafka topic, its not a hard concept to get your head around. But behind the scenes there’s a lot more going on than meets the eye.
Say we’re consuming messages from a Topic and our Consumer crashes. Once we realise that the world isn’t ending, we recover from the crash and we start consuming again. We start receiving messages exactly where we left off from, its kinda neat.
The Offset is a piece of metadata, an integer value that continually increases for each message that is received in a partition. Each message will have a unique Offset value in a partition.
When a Consumer reads the messages from the Partition it lets Kafka know the Offset of the last consumed message. This Offset is stored in a Topic named _consumer_offsets, in doing this a consumer can stop and restart without forgetting which messages it has consumed.
When we create our Consumers, they have a set of default properties which we can override or we can just leave the default values in effect.
There are two properties that are driving this behaviour.
有两个属性需要关注。
1 2 3 4 5
enable.auto.commit
auto.commit.interval.ms
The first property enable.auto.commit has a default value of true and the second property auto.commit.interval.ms has a default value of 5000. These values are correct for Blizzards node-rdkafka client and the Java KafkaConsumer client but other libraries may differ.
enable.auto.commit 的默认值是 true;就是默认采用自动提交的机制。
auto.commit.interval.ms 的默认值是 5000,单位是毫秒。
So by default every 5 seconds a Consumer is going to commit its Offset to Kafka or every time data is fetched from the specified Topic it will commit the latest Offset.
Now in some scenarios this is the ideal behaviour but on other scenarios its not.
这样,在某些场景下,这是理想的表现,但是在其他场景下,并不是。
Say our Consumer is processing a message with an Offset of 100 and whilst processing it the Consumer fetches some more data, the Offset is commit and then the Consumer crashes. Upon coming back up it will start consuming messages from the most recent committed Offset, but how can we safely say that we haven’t lost messages and the Offset of the new message isn’t later then the one of the message been processed?
What we can do is commit the Offset of messages manually after processing them. This give us full control over when we consider a message dealt with, processed and ready to let Kafka know that.
Firstly we have to change the value of the enable.auto.commit property.
1
enable.auto.commit: false
When we change this property the auto.commit.interval.ms value isnt taken into consideration.
So now we can commit our Offset manually after the processing has taken place and if the Consumer crashes whilst processing a message it will start consuming from that same Offset, no messages lost.
我们把这个参数设置为 false ,就会由我们自己手动地来处理这个事情。
Both the clients mentioned earlier in this article have methods exposed to commit the Offset.
For further reading on the clients check out the links below.
但是这里需要注意的是当一个线程已经死亡,却没有释放相应的槽位,并在垃圾收集器释放该槽位之前,再次使用了这个线程 ID 并为其分配一个新的槽位。对于新的线程来说,检查全局列表并且重用相同的槽位(如果以前的实例使用了它的话),这是非常重要的。因为垃圾收集器线程和写入者线程可能同时尝试修改全局列表,所以同样也需要使用某种锁定机制。
二、Ring Buffer的优点
我们使用 Ring Buffer 这种数据结构,是因为它给我们提供了可靠的消息传递特性。这个理由就足够了,不过它还有一些其他的优点。
首先,Ring Buffer 比链表要快,因为它是数组,而且有一个容易预测的访问模式。这很不错,对 CPU 高速缓存友好 (CPU-cache-friendly)-数据可以在硬件层面预加载到高速缓存,因此 CPU 不需要经常回到主内存 RAM 里去寻找 Ring Buffer 的下一条数据。
使用锁时,线程获取锁是一种悲观锁策略,即假设每一次执行临界区代码都会产生冲突,所以当前线程获取到锁的时候同时也会阻塞其他线程获取该锁。而CAS操作(又称为无锁操作)是一种乐观锁策略,它假设所有线程访问共享资源的时候不会出现冲突,既然不会出现冲突自然而然就不会阻塞其他线程的操作。因此,线程就不会出现阻塞停顿的状态。那么,如果出现冲突了怎么办?无锁操作是使用**CAS(compare and swap)**又叫做比较交换来鉴别线程是否出现冲突,出现冲突就重试当前操作直到没有冲突为止。
在同步的时候是获取对象的monitor,即获取到对象的锁。那么对象的锁怎么理解?无非就是类似对对象的一个标志,那么这个标志就是存放在Java对象的对象头。Java对象头里的Mark Word里默认的存放的对象的Hashcode,分代年龄和锁标记位。32为JVM Mark Word默认存储结构为(注:java对象头以及下面的锁状态变化摘自《java并发编程的艺术》一书,该书我认为写的足够好,就没在自己组织语言班门弄斧了):
Mark Word存储结构
如图在Mark Word会默认存放hasdcode,年龄值以及锁标志位等信息。
Java SE 1.6中,锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态会随着竞争情况逐渐升级。锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率。对象的MarkWord变化为下图:
线程在执行同步块之前,JVM会先在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中,官方称为Displaced Mark Word。然后线程尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁
解锁
轻量级解锁时,会使用原子的CAS操作将Displaced Mark Word替换回到对象头,如果成功,则表示没有竞争发生。如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁。下图是两个线程同时争夺锁,导致锁膨胀的流程图。
<?xml version="1.0" encoding="UTF-8"?> <configuration> <include resource="org/springframework/boot/logging/logback/defaults.xml"/> ? <springProperty scope="context" name="springAppName" source="spring.application.name"/> <springProperty scope="context" name="ELK_FILEBEAT_PATH" source="elk.filebeat_path" defaultValue="/PATHTO/log"/> <springProperty scope="context" name="ELK_URL" source="elk.url" defaultValue="127.0.0.1"/>? <springProperty scope="context" name="ELK_QUEUE_SIZE" source="elk.queue_size" defaultValue="8192"/>? <!-- Example for logging into the build folder of your project --> <property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>?
<!-- You can override this to have a custom pattern --> <property name="CONSOLE_LOG_PATTERN" value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(%X{transNo}){faint} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<!-- Appender to log to console --> <appender name="console" class="ch.qos.logback.core.ConsoleAppender"> <filter class="ch.qos.logback.classic.filter.ThresholdFilter"> <!-- Minimum logging level to be presented in the console logs--> <level>DEBUG</level> </filter> <encoder> <pattern>${CONSOLE_LOG_PATTERN}</pattern> <charset>utf8</charset> </encoder> </appender>
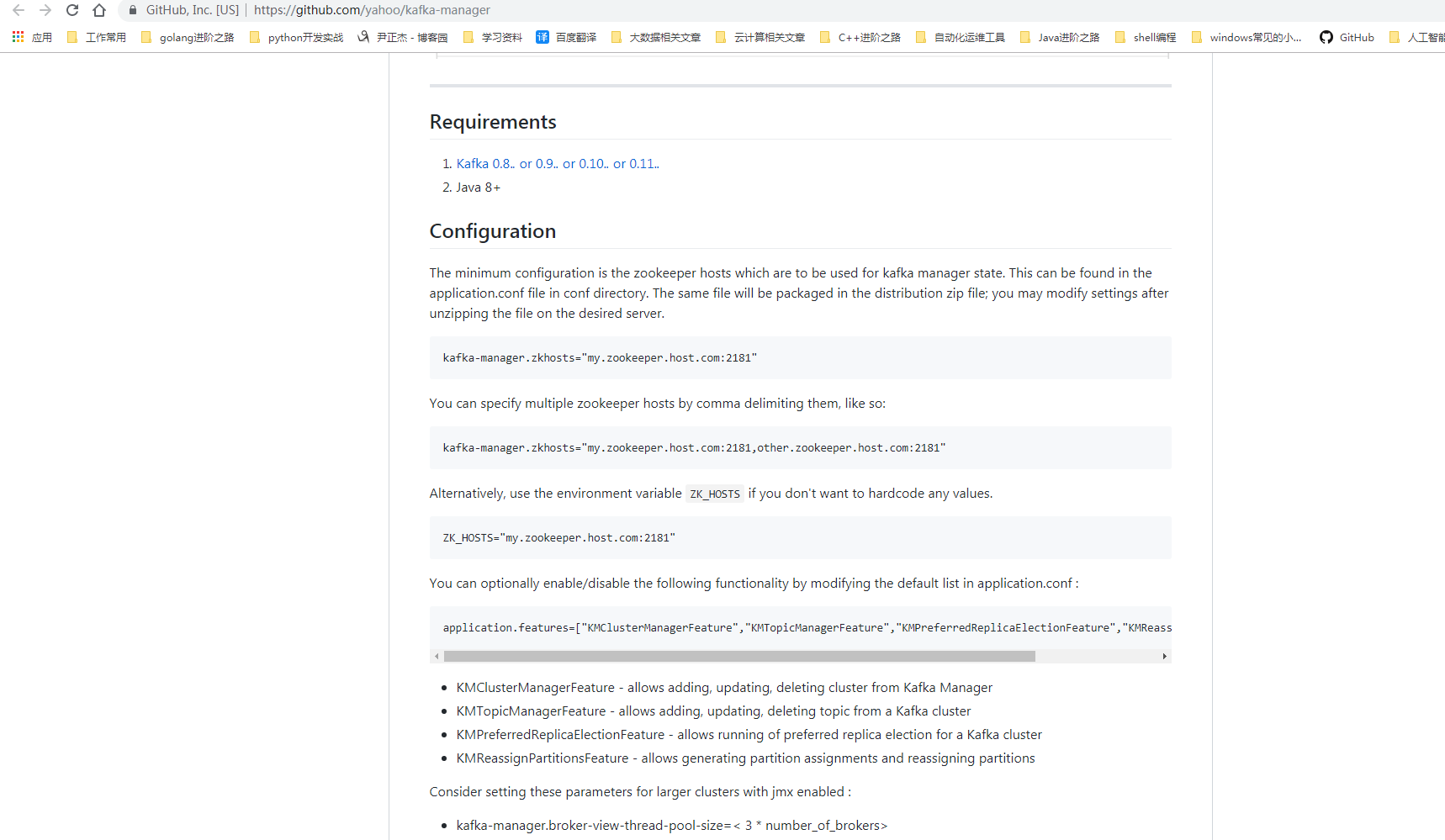

 [root@node108.yinzhengjie.org.cn ~]# yum -y install unzip zip
[root@node108.yinzhengjie.org.cn ~]# yum -y install unzip zip


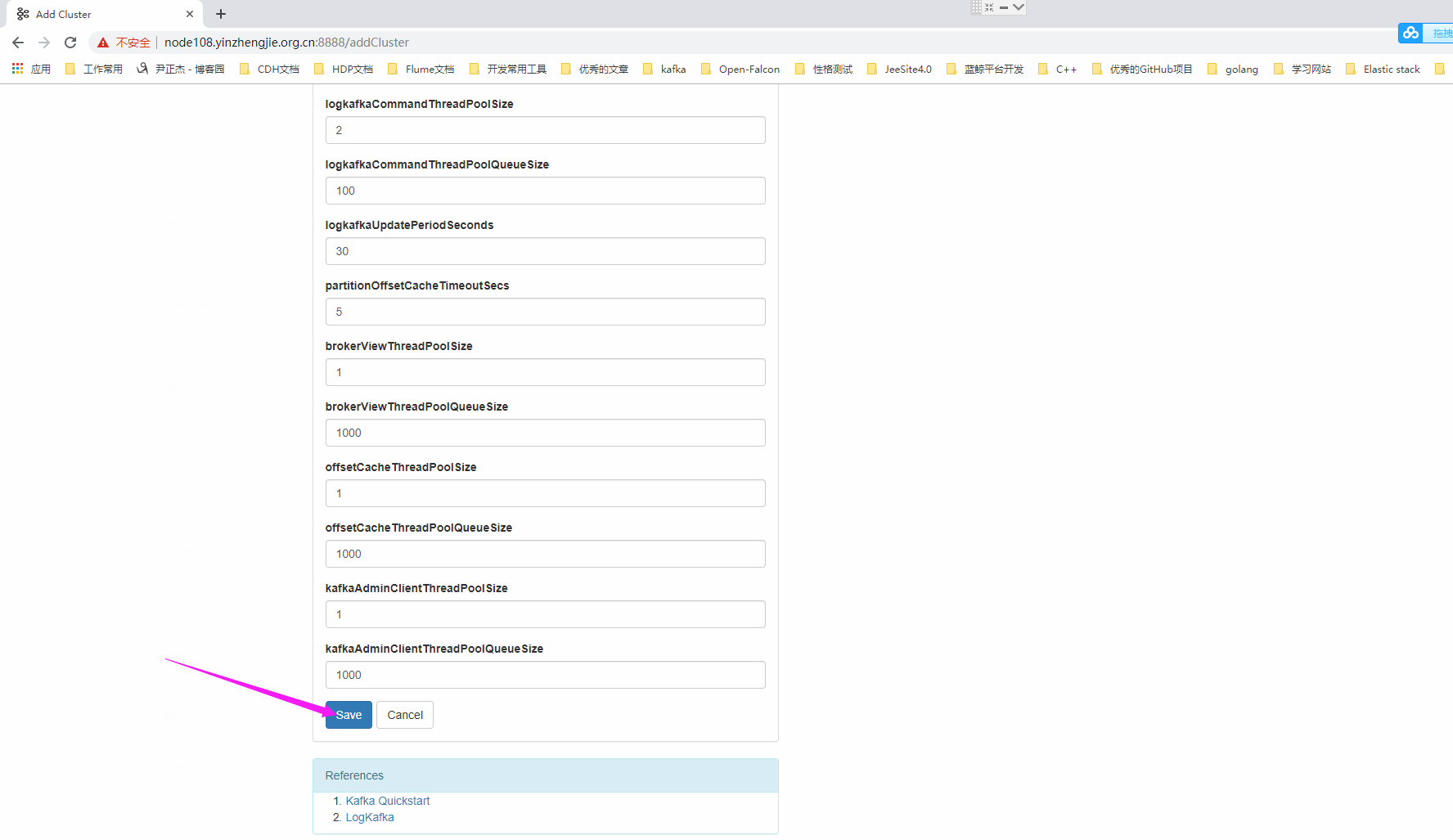
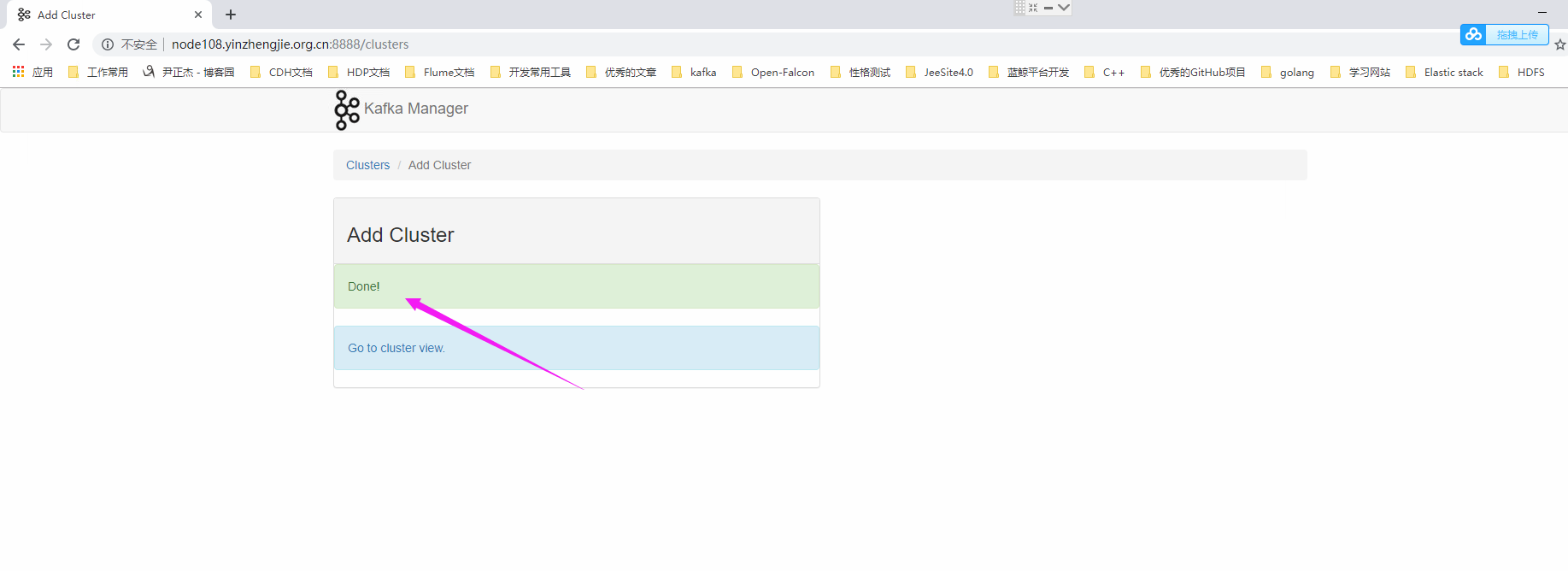

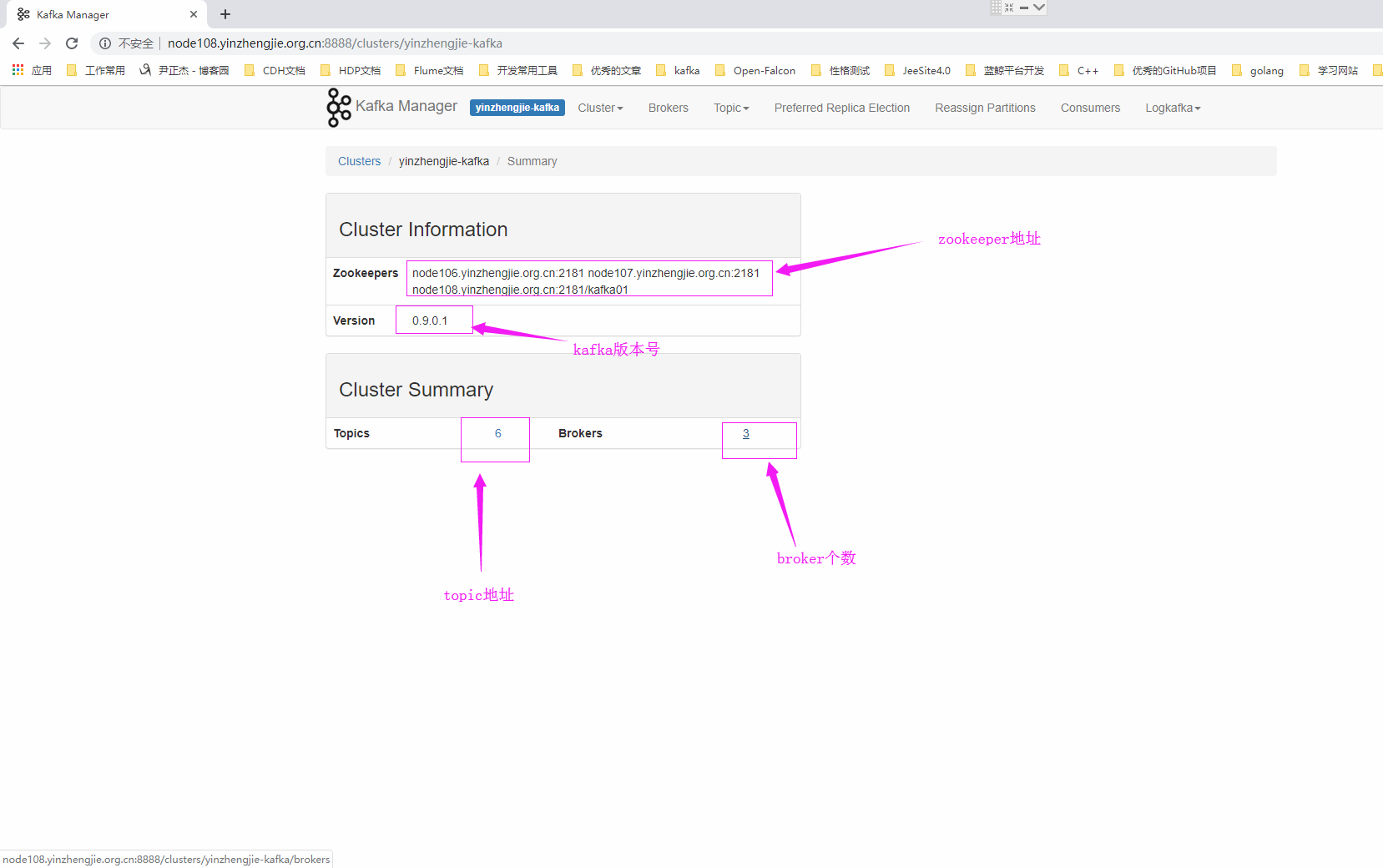

 *
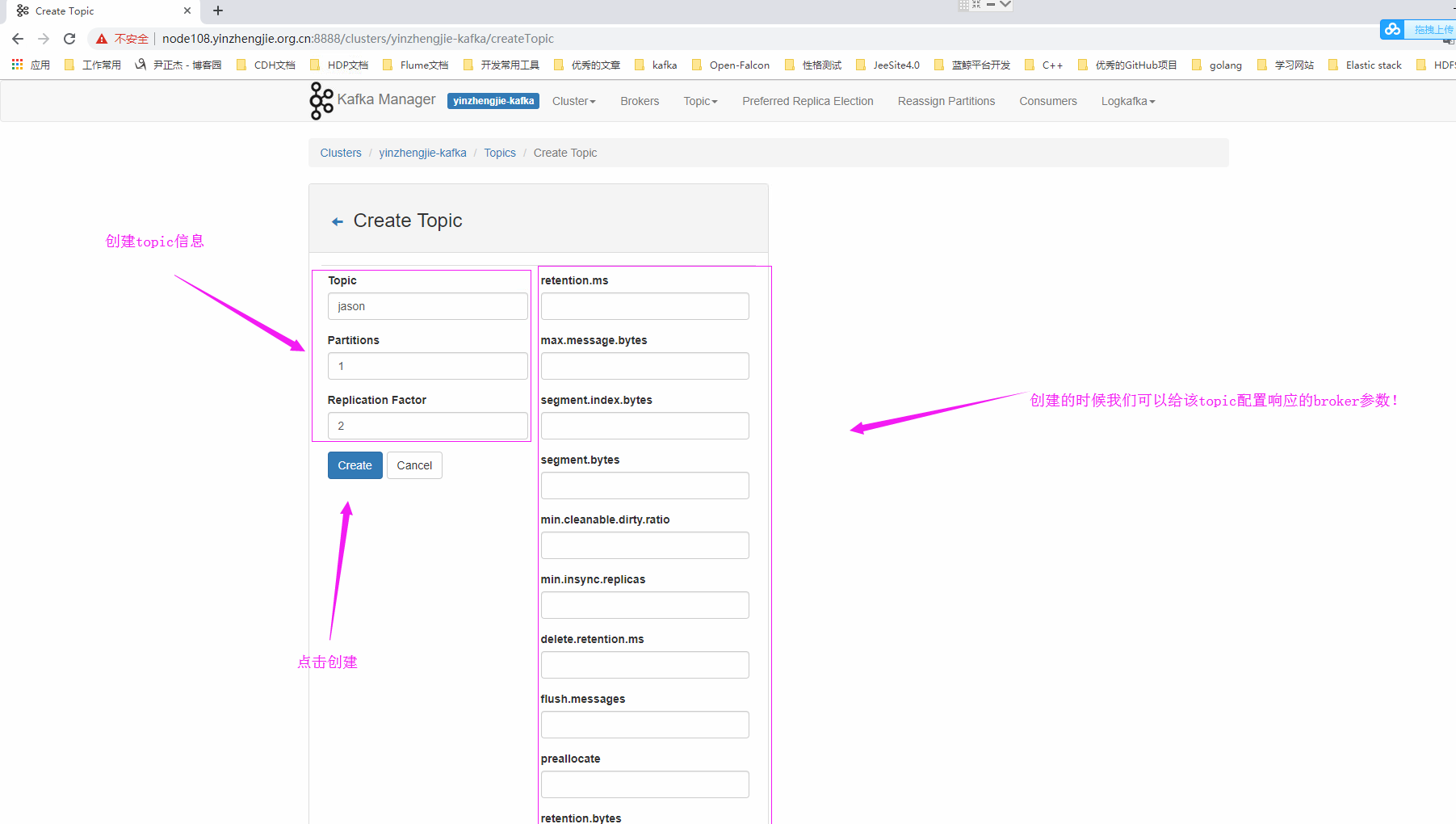
*
 *
*