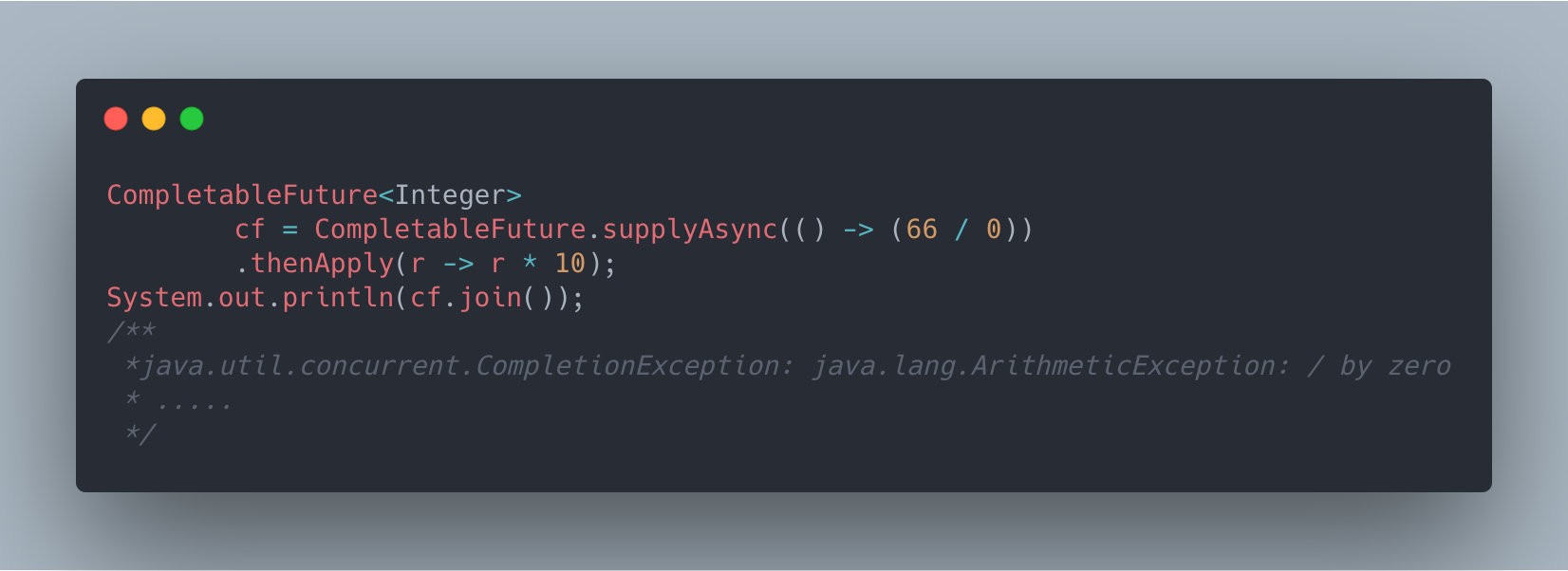
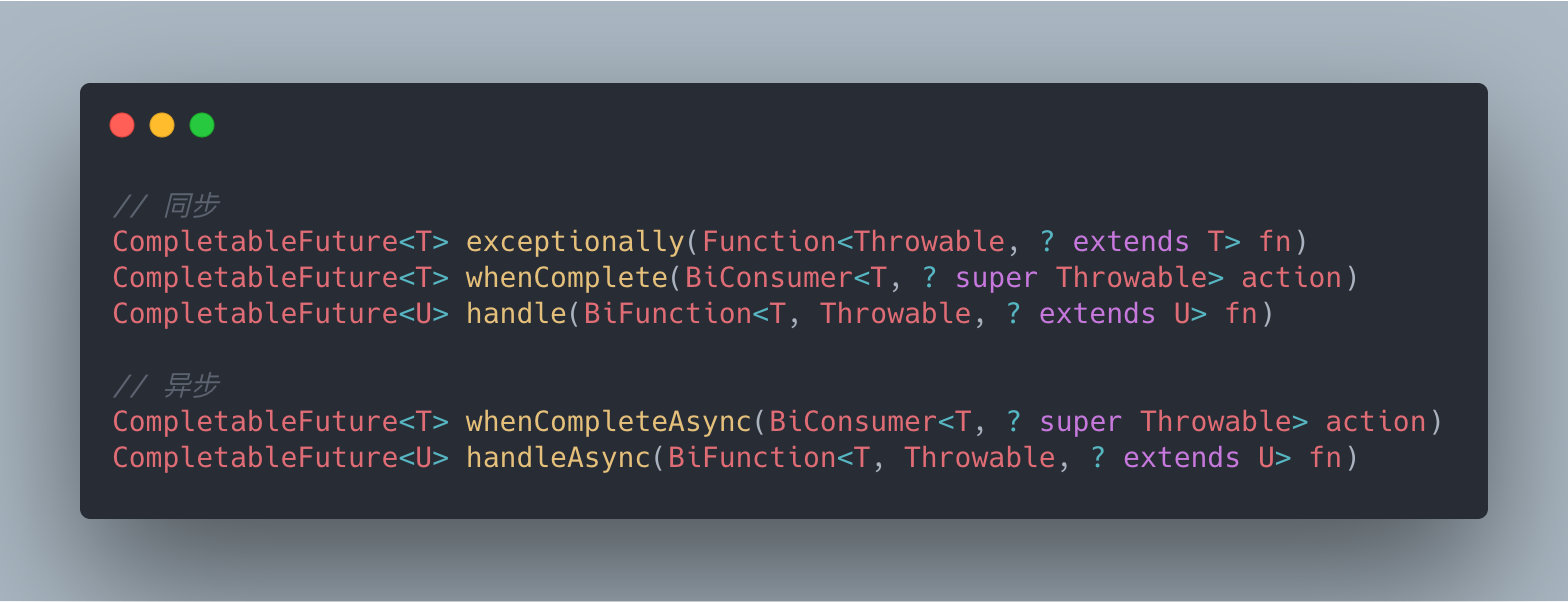
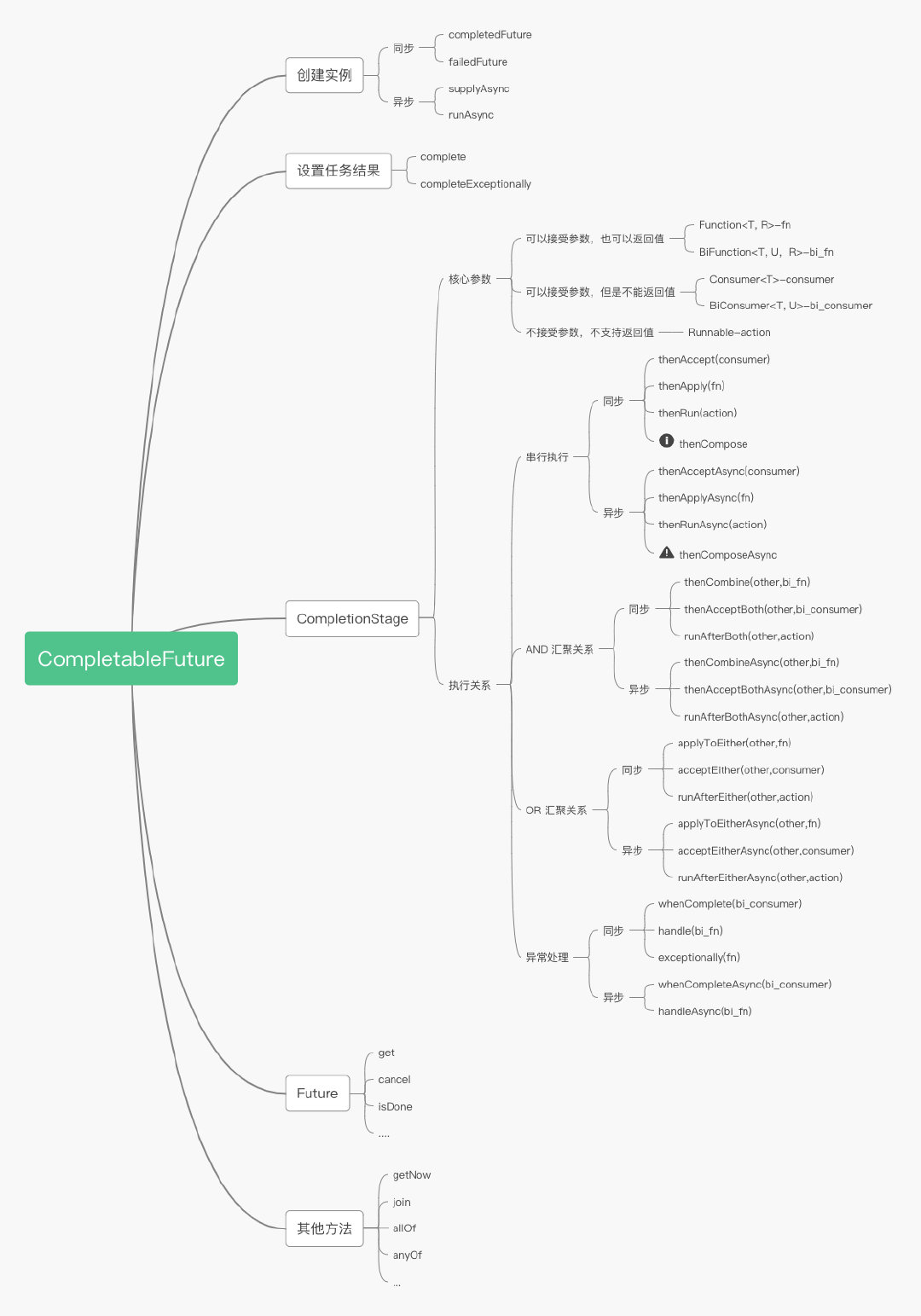
This statement declares the direction of the Flowchart.
This declares the graph is oriented from top to bottom (TD or TB).
graph TD
Start --> Stop
StartStop
This declares the graph is oriented from left to right (LR).
graph LR
Start --> Stop
StartStop
Flowchart Orientation
Possible FlowChart orientations are:
TB - top to bottom
TD - top-down/ same as top to bottom
BT - bottom to top
RL - right to left
LR - left to right
Flowcharts
This renders a flowchart that allows for features such as: more arrow types, multi directional arrows, and linking to and from subgraphs.
Apart from the graph type, the syntax is the same. This is currently experimental but when the beta period is over, both the graph and flowchart keywords will render in the new way. This means it is ok to start beta testing flowcharts.
Important note Do not type the word “end” as a Flowchart node. Capitalize all or any one the letters to keep the flowchart from breaking, i.e, “End” or “END”. Or you can apply this workaround.**
Nodes & shapes
A node (default)
graph LR
id
id
Note The id is what is displayed in the box.
A node with text
It is also possible to set text in the box that differs from the id. If this is done several times, it is the last text found for the node that will be used. Also if you define edges for the node later on, you can omit text definitions. The one previously defined will be used when rendering the box.
graph LR
id1[This is the text in the box]
This is the text in the box
Node Shapes
A node with round edges
graph LR
id1(This is the text in the box)
This is the text in the box
A stadium-shaped node
graph LR
id1([This is the text in the box])
This is the text in the box
A node in a subroutine shape
graph LR
id1[[This is the text in the box]]
This is the text in the box
A node in a cylindrical shape
graph LR
id1[(Database)]
Database
A node in the form of a circle
graph LR
id1((This is the text in the circle))
This is the text in the circle
A node in an asymetric shape
graph LR
id1>This is the text in the box]
This is the text in the box
Currently only the shape above is possible and not its mirror. This might change with future releases.
A node (rhombus)
graph LR
id1{This is the text in the box}
This is the text in the box
A hexagon node
graph LR
id1{{This is the text in the box}}
This is the text in the box
Parallelogram
graph TD
id1[/This is the text in the box/]
This is the text in the box
Parallelogram alt
graph TD
id1[\This is the text in the box\]
This is the text in the box
Trapezoid
graph TD
A[/Christmas\]
Christmas
Trapezoid alt
graph TD
B[\Go shopping/]
Go shopping
Links between nodes
Nodes can be connected with links/edges. It is possible to have different types of links or attach a text string to a link.
A link with arrow head
graph LR
A-->B
AB
An open link
graph LR
A --- B
AB
Text on links
graph LR
A-- This is the text! ---B
This is the textAB
or
graph LR
A---|This is the text|B
This is the textAB
A link with arrow head and text
graph LR
A-->|text|B
textAB
or
graph LR
A-- text -->B
textAB
Dotted link
graph LR;
A-.->B;
AB
Dotted link with text
graph LR
A-. text .-> B
textAB
Thick link
graph LR
A ==> B
AB
Thick link with text
graph LR
A == text ==> B
textAB
Chaining of links
It is possible declare many links in the same line as per below:
graph LR
A -- text --> B -- text2 --> C
texttext2ABC
It is also possible to declare multiple nodes links in the same line as per below:
graph LR
a --> b & c--> d
abcd
You can then describe dependencies in a very expressive way. Like the one-liner below:
graph TB
A & B--> C & D
ABCD
If you describe the same diagram using the the basic syntax, it will take four lines. A word of warning, one could go overboard with this making the graph harder to read in markdown form. The Swedish word lagom comes to mind. It means, not too much and not too little. This goes for expressive syntaxes as well.
graph TB
A --> C
A --> D
B --> C
B --> D
Beta: New arrow types
When using flowchart instead of graph there are new types of arrows supported as per below:
1 2 3
flowchart LR A --o B B --x C
ABC
Beta: Multi directional arrows
When using flowchart instead of graph there is the possibility to use multidirectional arrows.
1 2 3 4
flowchart LR A o--o B B <--> C C x--x D
ABCD
Minimum length of a link
Each node in the flowchart is ultimately assigned to a rank in the rendered graph, i.e. to a vertical or horizontal level (depending on the flowchart orientation), based on the nodes to which it is linked. By default, links can span any number of ranks, but you can ask for any link to be longer than the others by adding extra dashes in the link definition.
In the following example, two extra dashes are added in the link from node B to node E, so that it spans two more ranks than regular links:
graph TD
A[Start] --> B{Is it?};
B -->|Yes| C[OK];
C --> D[Rethink];
D --> B;
B ---->|No| E[End];
YesNoStartIs it?OKRethinkEnd
Note Links may still be made longer than the requested number of ranks by the rendering engine to accommodate other requests.
When the link label is written in the middle of the link, the extra dashes must be added on the right side of the link. The following example is equivalent to the previous one:
graph TD
A[Start] --> B{Is it?};
B -- Yes --> C[OK];
C --> D[Rethink];
D --> B;
B -- No ----> E[End];
YesNoStartIs it?OKRethinkEnd
For dotted or thick links, the characters to add are equals signs or dots, as summed up in the following table:
Length
1
2
3
Normal
---
----
-----
Normal with arrow
-->
--->
---->
Thick
===
====
=====
Thick with arrow
==>
===>
====>
Dotted
-.-
-..-
-...-
Dotted with arrow
-.->
-..->
-...->
Special characters that break syntax
It is possible to put text within quotes in order to render more troublesome characters. As in the example below:
graph LR
id1["This is the (text) in the box"]
This is the (text) in the box
Entity codes to escape characters
It is possible to escape characters using the syntax examplified here.
1 2
graph LR A["A double quote:#quot;"] -->B["A dec char:#9829;"]
A double quote:”A dec char:♥
Subgraphs
1 2 3
subgraph title graph definition end
An example below:
graph TB
c1-->a2
subgraph one
a1-->a2
end
subgraph two
b1-->b2
end
subgraph three
c1-->c2
end
threetwoonec2c1b2b1a2a1
You can also set an excplicit id for the subgraph.
graph TB
c1-->a2
subgraph ide1 [one]
a1-->a2
end
onea2a1c1
Beta: flowcharts
With the graphtype flowcharts it is also possible to set edges to and from subgraphs as in the graph below.
flowchart TB
c1-->a2
subgraph one
a1-->a2
end
subgraph two
b1-->b2
end
subgraph three
c1-->c2
end
one --> two
three --> two
two --> c2
threeonec2c1twob2b1a2a1
Interaction
It is possible to bind a click event to a node, the click can lead to either a javascript callback or to a link which will be opened in a new browser tab. Note: This functionality is disabled when using securityLevel='strict' and enabled when using securityLevel='loose'.
1
click nodeId callback
nodeId is the id of the node
callback is the name of a javascript function defined on the page displaying the graph, the function will be called with the nodeId as parameter.
Examples of tooltip usage below:
<script>
var callback = function(){
alert('A callback was triggered');
}
</script>
graph LR;
A-->B;
click A callback "Tooltip for a callback"
click B "http://www.github.com" "This is a tooltip for a link"
The tooltip text is surrounded in double quotes. The styles of the tooltip are set by the class .mermaidTooltip.
Success The tooltip functionality and the ability to link to urls are available from version 0.5.2.
?> Due to limitations with how Docsify handles JavaScript callback functions, an alternate working demo for the above code can be viewed at this jsfiddle.
Links are opened in the same browser tab/window by default. It is possible to change this by adding a link target to the click definition (_self, _blank, _parent and _top are supported):
graph LR;
A-->B;
B-->C;
click A "http://www.github.com"
click B "http://www.github.com" "Open this in a new tab" _blank
<body> <div class="mermaid"> graph LR; A-->B; click A callback "Tooltip" click B "http://www.github.com" "This is a link" </div>
<script> var callback = function(){ alert('A callback was triggered'); } var config = { startOnLoad:true, flowchart:{ useMaxWidth:true, htmlLabels:true, curve:'cardinal', }, securityLevel:'loose', };
mermaid.initialize(config); </script> </body>
Comments
Comments can be entered within a flow diagram, which will be ignored by the parser. Comments need to be on their own line, and must be prefaced with %% (double percent signs). Any text after the start of the comment to the next newline will be treated as a comment, including any flow syntax
graph LR
%% this is a comment A -- text --> B{node}
A -- text --> B -- text2 --> C
Styling and classes
Styling links
It is possible to style links. For instance you might want to style a link that is going backwards in the flow. As links have no ids in the same way as nodes, some other way of deciding what style the links should be attached to is required. Instead of ids, the order number of when the link was defined in the graph is used. In the example below the style defined in the linkStyle statement will belong to the fourth link in the graph:
More convenient then defining the style every time is to define a class of styles and attach this class to the nodes that should have a different look.
Graph declarations with spaces between vertices and link and without semicolon
In graph declarations, the statements also can now end without a semicolon. After release 0.2.16, ending a graph statement with semicolon is just optional. So the below graph declaration is also valid along with the old declarations of the graph.
A single space is allowed between vertices and the link. However there should not be any space between a vertex and its text and a link and its text. The old syntax of graph declaration will also work and hence this new feature is optional and is introduce to improve readability.
Below is the new declaration of the graph edges which is also valid along with the old declaration of the graph edges.
graph LR
A[Hard edge] -->|Link text| B(Round edge)
B --> C{Decision}
C -->|One| D[Result one]
C -->|Two| E[Result two]
Link textOneTwoHard edgeRound edgeDecisionResult oneResult two
Configuration…
Is it possible to adjust the width of the rendered flowchart.
This is done by defining mermaid.flowchartConfig or by the CLI to use a json file with the configuration. How to use the CLI is described in the mermaidCLI page. mermaid.flowchartConfig can be set to a JSON string with config parameters or the corresponding object.
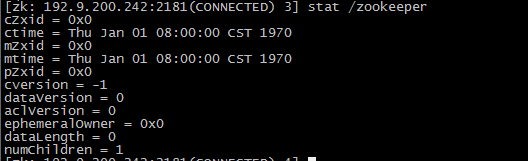
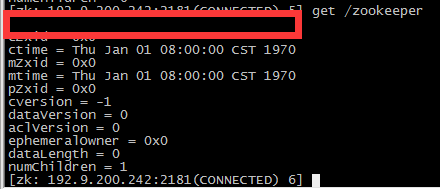
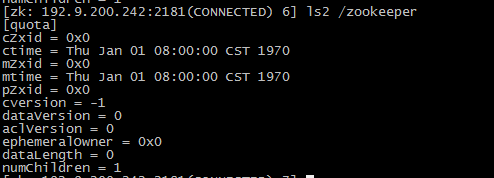
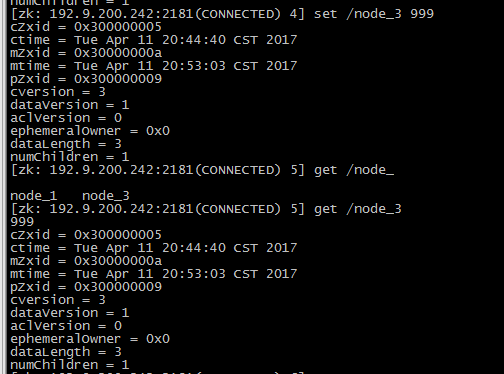
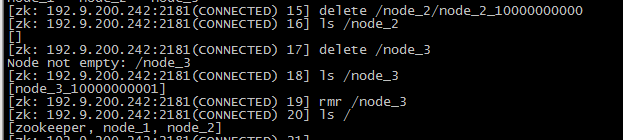
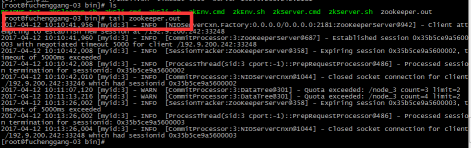
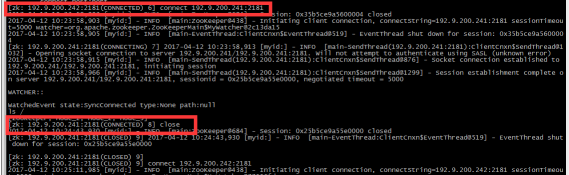
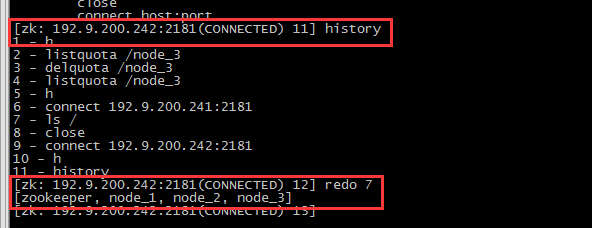
Curator是Netflix公司开源的一套zookeeper客户端框架,解决了很多Zookeeper客户端非常底层的细节开发工作,包括连接重连、反复注册Watcher和NodeExistsException异常等等。Patrixck Hunt(Zookeeper)以一句“Guava is to Java that Curator to Zookeeper”给Curator予高度评价。 引子和趣闻: Zookeeper名字的由来是比较有趣的,下面的片段摘抄自《从PAXOS到ZOOKEEPER分布式一致性原理与实践》一书: Zookeeper最早起源于雅虎的研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型的系统需要依赖一个类似的系统进行分布式协调,但是这些系统往往存在分布式单点问题。所以雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架。在立项初期,考虑到很多项目都是用动物的名字来命名的(例如著名的Pig项目),雅虎的工程师希望给这个项目也取一个动物的名字。时任研究院的首席科学家Raghu Ramakrishnan开玩笑说:再这样下去,我们这儿就变成动物园了。此话一出,大家纷纷表示就叫动物园管理员吧——因为各个以动物命名的分布式组件放在一起,雅虎的整个分布式系统看上去就像一个大型的动物园了,而Zookeeper正好用来进行分布式环境的协调——于是,Zookeeper的名字由此诞生了。